A RAID system requires at least two storage media which are to be viewed as a combination. The advantages of RAID systems are as follows:
- Redundancy / Increased reliability
- Higher data transfer rate
- Creation of large logical drives
- Replacement of hard drives during operation
- Increase in memory during operation
How a RAID system is constructed is specified by the RAID level (usually RAID 0, RAID 1 and RAID 5).
Hardware RAID / Software RAID
Hardware RAID uses a RAID controller. An electronic component, usually near the hard drives. The CPU on the controller means that a large part of the computing load can take place on the controller and the main CPU can be relieved.With software RAID, the RAID controlling is completely taken over by the computer. Modern operating systems (macOS, FreeBSD, OpenBSD, Linux, Windows ...) are capable of this. Here, the hard drives are connected directly to the mainboard or computer. After the hard drives have been integrated into the computer, the RAID is implemented using software.
The advantage is that no extra hardware is required, such as a RAID controller. Another advantage is that if a crash occurs, the hard drives can be read or restored more easily.
Disadvantages are the higher load on the computer, as the main CPU takes over the RAID organization and of course needs computing power for this. Another disadvantage is the loss of data in the event of a power failure. If you don't want the data to be lost, you need to use a UPS (uninterruptible power supply) with software RAID.
RAID 0 (striping)
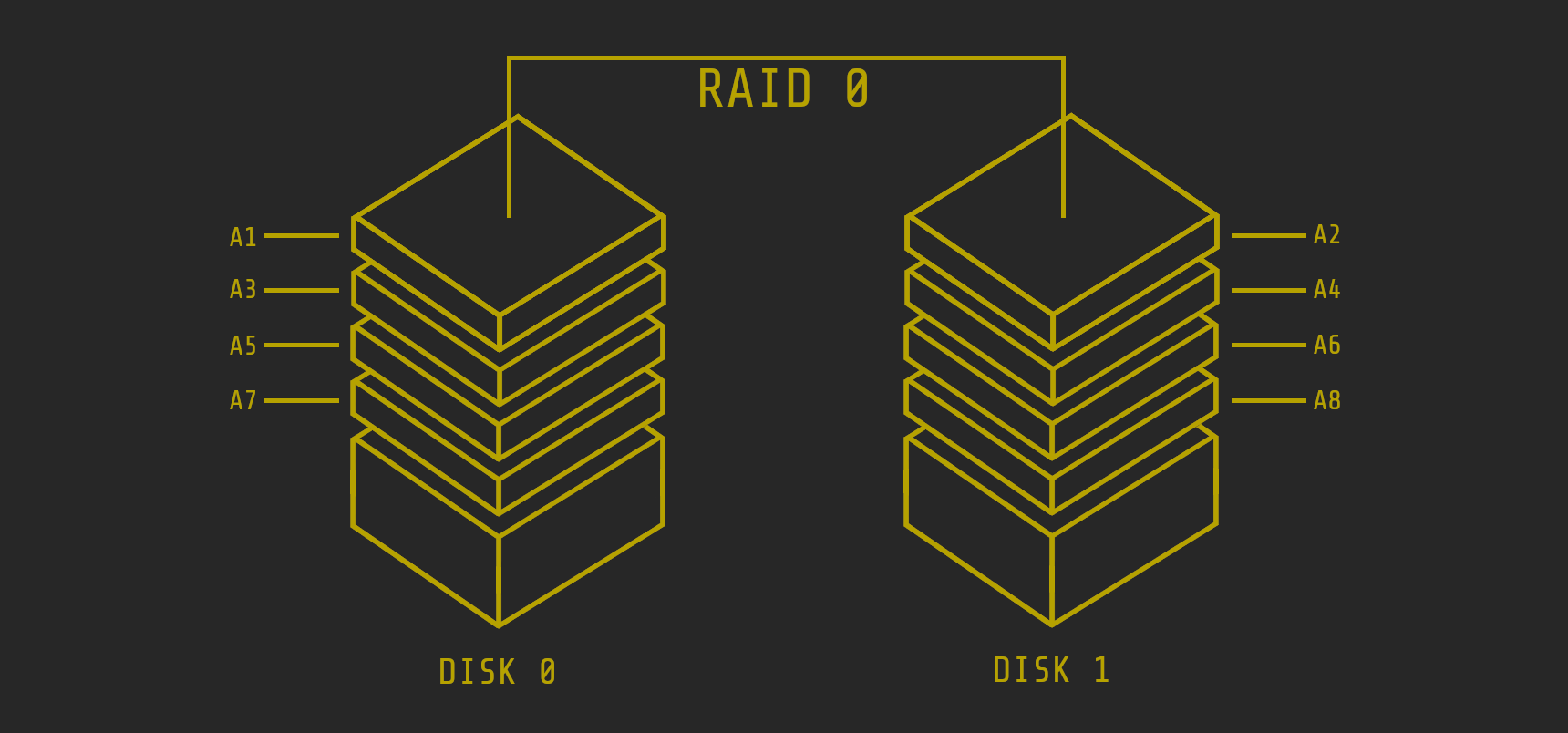
Strictly speaking, RAID 0 is not a real RAID system because the system lacks redundancy. With RAID 0, the hard drives are divided into connected blocks of the same size and then arranged in a zippered manner to form one large hard drive. Since the data or access to the hard drives can run in parallel, this results in higher data transfer rates. The disadvantage of RAID 0 is that if a hard drive fails, it is usually almost impossible to save the data. Therefore, a RAID 0 system should only be used when redundancy is not an issue, usually where large amounts of data need to be read quickly. Audio and video playback are the most common areas of application.
RAID 1 (mirroring)
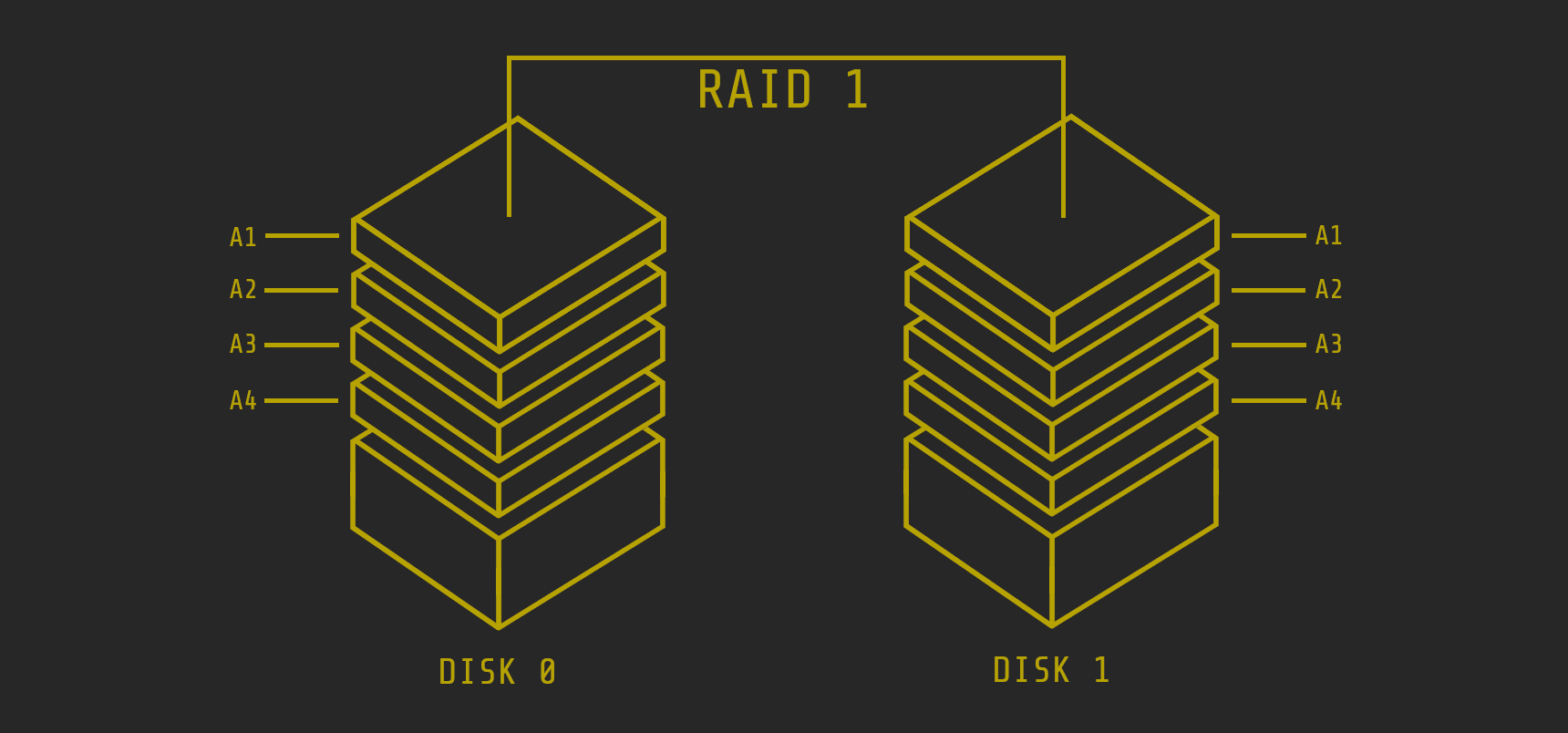
At least 2 hard drives are required for a RAID 1 array. In this array, the same data is stored on all hard drives (mirroring), which means that, in contrast to RAID 0, there is redundancy, which makes it significantly more fail-safe. The maximum capacity of the array is as large as the smallest hard drive used. A big advantage over other arrays is that the same data is stored on all hard drives and the hard drives can normally function and be operated independently of each other. So if one disk fails, the data is still on the other. However, this should not be confused with a backup. In the event of attacks, virus attacks or similar, the malware ends up directly on all disks. If someone uses an exploit to break into the array and destroy a disk, the exploit is also on the other disks "thanks" to redundancy.
Another advantage of RAID 1 arrays is that the reading performance increases enormously, since the same data is stored on both disks, which means that the reading speed is even doubled.
RAID 5 (blocklevel striping + distributed parity information)
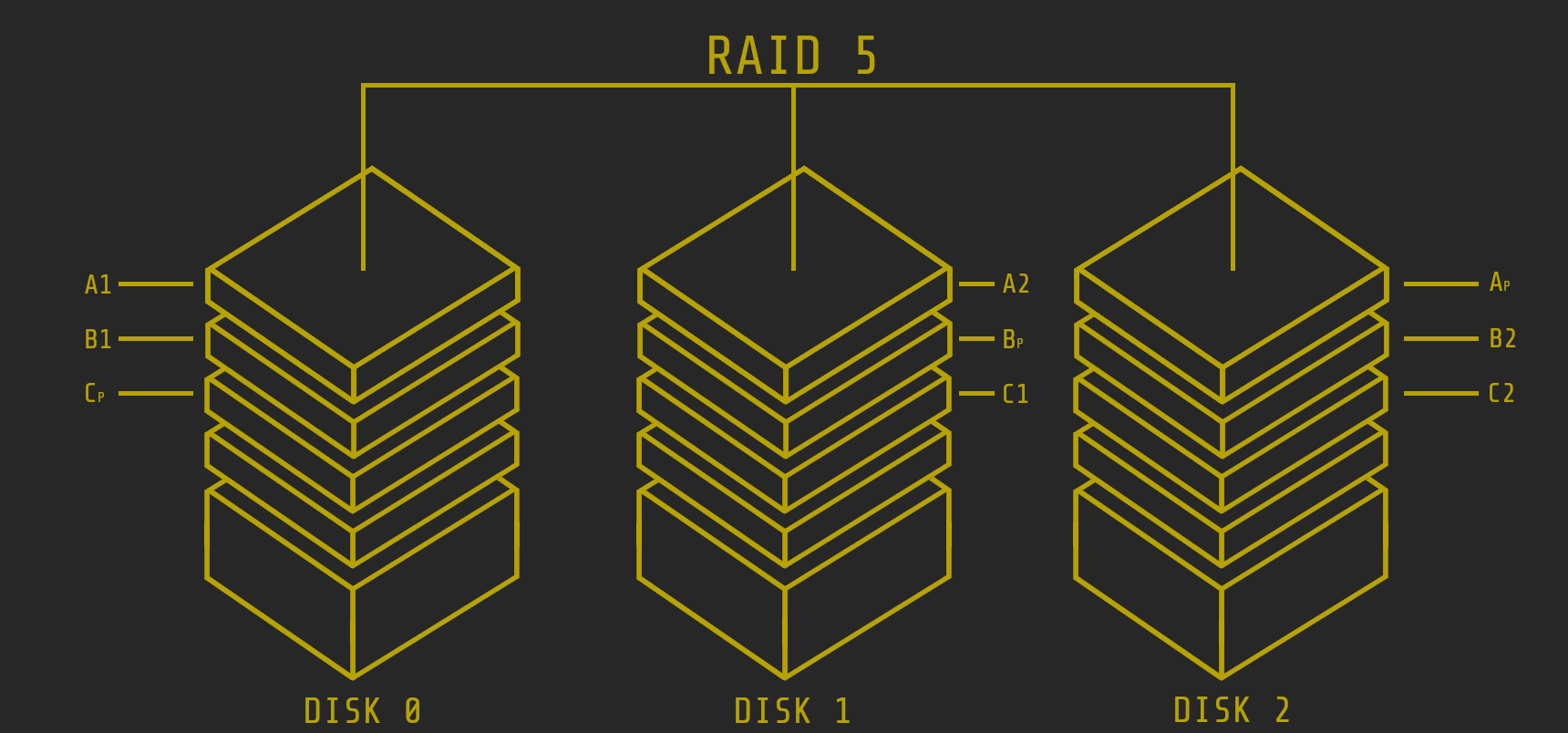
With RAID 5, the distribution is a little different. With RAID 5, the data is distributed across the different disks using striping, similar to RAID 0. There is also parity information that is distributed at block level. Logical groups are formed with the data blocks of the same address. There is always one block per group that contains the parity information.
A1 / A2 = data blocks AP = data block with parity data
With four hard drives of 1 TB each, 3 TB of storage is available at the end and 1 TB is reserved for the parity data.
User data and parity data are distributed across all disks. RAID 5 offers increased data throughput when reading and additional redundancy. Since RAID 5 is relatively inexpensive to operate, it is one of the most popular RAID arrays. Three or five hard drives are often found in RAID 5, since the number of hard drives influences the write performance.
The RAID types can also be combined with each other. This creates RAID 01 arrays or RAID 03/RAID 30, RAID 05, RAID 10, etc.
These were the most common RAID arrays. There are a few more. There are unconventional arrays or ones that have become meaningless, such as RAID 2, RAID 3, RAID 4, RAID 6, RAIDn RAID DP, etc.
I think I've explained the most important things here and described the basics to you. There are countless specialist books on RAID that go into the subject in more depth. I think this is sufficient for future projects.
[~] BACK